大数据已成为驱动当今社会数字化、智能化转型的核心引擎。它并非单一概念,而是一个由多重要素构成的复杂体系。要全面理解大数据,必须系统把握其构成、特点、技术、处理与应用这五个核心要素,而这一切的起点,正是数据采集。
一、 大数据构成:多样来源的汇聚
大数据的构成是其物理基础,指的是数据本身的来源与形态。它主要包含三大类数据:
1. 结构化数据:存储在关系型数据库中,具有清晰定义的格式,如表格、财务报表、客户信息等。
2. 半结构化数据:虽不符合严格的数据库表结构,但包含标签或其他标记来分隔数据元素,如XML、JSON文件、电子邮件、HTML网页等。
3. 非结构化数据:没有预定义的数据模型,格式多样,占当今数据总量的80%以上。例如,社交媒体文本、图片、音频、视频、传感器日志等。
这些数据共同构成了大数据庞大而复杂的“原材料”库。
二、 大数据核心特点:4V+模型
大数据的价值与挑战均源于其独特特点,通常用“4V”模型概括:
1. Volume(体量大):数据量从TB级别跃升到PB乃至EB级别,规模巨大。
2. Variety(种类多):如上所述,数据类型极其丰富,涵盖结构化、半结构化和非结构化数据。
3. Velocity(速度快):数据生成、流转和处理的速度极快,要求实时或准实时响应,如金融交易、物联网传感数据流。
4. Value(价值密度低):海量数据中蕴含高价值的信息比例相对较低,需要通过深度挖掘才能提取出宝贵洞察。
业界还常补充Veracity(真实性),强调数据质量与可信度的重要性。
三、 大数据关键技术:支撑体系的基石
处理如此庞大的数据体量,离不开一系列关键技术的支撑:
1. 存储技术:如分布式文件系统(如HDFS)、NoSQL数据库(如MongoDB, Cassandra)、NewSQL数据库等,用于低成本、高可靠地存储海量异构数据。
2. 计算框架:以Hadoop的MapReduce和Apache Spark为核心,实现分布式并行计算,处理大规模数据集。
3. 资源管理与调度:如YARN、Kubernetes,负责高效管理和调度集群中的计算资源。
这些技术共同构成了大数据处理的基础设施。
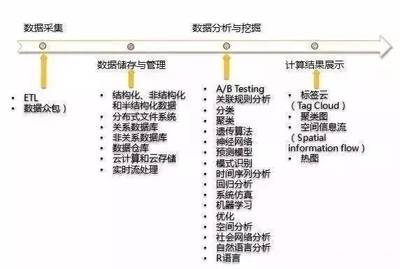
四、 大数据处理流程:从原始数据到智慧洞察
大数据的价值实现遵循一个完整的处理生命周期,主要包括:
- 数据采集与集成:这是整个流程的起点。通过ETL(提取、转换、加载)工具、网络爬虫、传感器、日志收集器(如Flume, Kafka)等技术,从各种异构源系统中汇聚数据。
- 数据存储与管理:将采集到的数据存入合适的存储系统,并进行有效组织和管理。
- 数据处理与分析:这是核心环节。包括数据清洗、转换、统计分析、机器学习建模、数据挖掘等,以发现模式、关联和趋势。
- 数据可视化与解释:将分析结果以图表、仪表盘等直观形式呈现,辅助决策。
五、 大数据应用:赋能千行百业
大数据技术已渗透到各个领域,创造巨大价值:
- 商业智能:客户细分、精准营销、需求预测、供应链优化。
- 金融服务:欺诈检测、风险评估、算法交易。
- 医疗健康:疾病预测、个性化治疗、药物研发、医疗影像分析。
- 智慧城市:交通流量管理、公共安全监控、能源智能调度。
- 工业制造:预测性维护、工艺优化、质量控制。
聚焦起点:数据采集
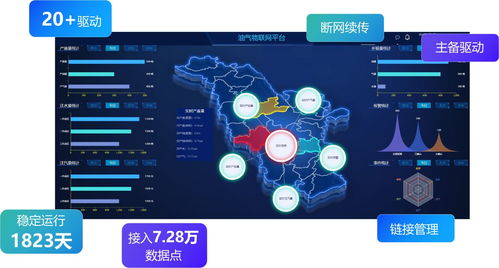
正如您所特别指出的,数据采集是整个大数据价值链的首要环节和基石。没有高质量、多渠道的数据采集,后续所有处理与分析都将是“无米之炊”。现代数据采集技术正朝着实时化(流数据采集)、智能化(边缘计算预处理)和全面化(物联网、社交网络、业务系统全覆盖)的方向发展。它确保原始数据能源源不断地、可靠地汇入大数据平台,为后续的价值挖掘奠定坚实基础。
理解大数据,需要将其视为一个从构成(多样数据源)出发,具备鲜明特点,依托核心技术,经过系统化处理流程,最终在广泛应用场景中实现价值的完整生态系统。而数据采集,正是激活这个生态系统的第一把钥匙。